如何设计良好的 API
时间:2026-7-4 01:32 作者:独元殇 分类: 开发相关

首先就是选择一个好的产品,API 设计通常遵循产品的"基础资源",一个技术上出色的 API 无法拯救一个没人想用的产品。然而, 一个技术上糟糕的产品却可能让构建优雅的 API 几乎不可能实现 。
API 在我个人工作经历里,重要性,我觉得不比 数据库 要差。但是往往互联网上,到处都是教你设计优秀的软件,还有 Java 起头搞的乱七八糟的 设计模式 生态。
但是 API 之类的攻略、建议、教程,很少。
在非 AI 时代,API 是程序员花费很大时间设计和打磨的复杂产品。而且,很大程度上,API 跟网页设计师这种前端一样,只不过是给开发者搞的「前端」,一个看着难看要死的 API ,会很大程度上把一个后端软件、命令行软件的颜值给降低。
不过,我最近在 Hacker News 上读到了 GitHub 公司的员工,著名的软件工程师 Sean Goedecke 的一篇文章,关于良好 API 设计我所知的一切 ,这文章写的很切题意。
Hacker News 原文, 热度很高 : https://news.ycombinator.com/item?id=45006801
他的博客,每个月的访问量有一百多万,写的每篇文章都是很值得收藏的。
我来简单讲讲这文章说了什么。
产品有价值,就成功 90% 了
没人会在乎 API 多么优雅。
如果 API 设计的一塌糊涂,但是产品好,有用。也无所谓。
API 质量属于边际特性:只有当用户在两个基本等价的产品之间做选择时,它才会发挥作用。
你的产品足够吸引人,任何勉强可用的 API 都可以上线。
但是注意,糟糕的产品,是不可能有优雅的 API 的!你的软件架构必须得先优秀。
我就不举代码的例子了,看一个故事来理解意思吧(本故事有经 AI 润色):
一家餐馆把所有订单写在一卷很长的纸上。每张订单只写着“下一张订单在哪里”,像一条无限延伸的纸链。
顾客问:“请给我第 500 到第 520 张订单。”
服务员没法直接找到,只能从第一张开始,一张张往后翻。订单少时还能忍,几千张以后,每次查询都很慢。为了避免系统卡死,服务员只好规定:“每次最多翻 100 张。”这样第 101 张以后的订单,顾客可能永远拿不到。
API 就像餐馆的取餐窗口。窗口设计得再漂亮,也改变不了后厨混乱的存放方式。
如果订单一开始就按“订单编号、桌号、时间”分别存好,服务员就能直接取出指定范围。API 也可以自然地提供分页、搜索和排序。
那么 API 方面的注意事项呢?
平衡 熟悉性与灵活性
第一点就很反认知:好的 API 是无聊的。一个有趣的 API 就是糟糕的 API。
为什么,因为 API 很难更改 !!!
就跟前端 JS 里至今保留着丑陋的 innerHTML 这种极其尴尬的 API 一样。但是没办法,只要发布,并且有人用,那么就得定死了。
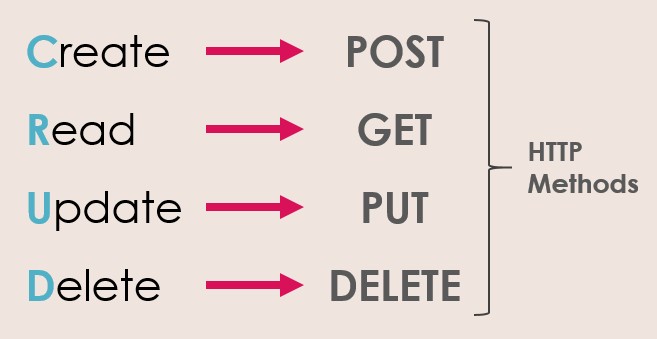
所以设计 API 的人,都想要一次就设计对!所以都喜欢简单,但是又想保持灵活性。就跟这几年超级流行的 REST api 一样,不用读文档,一眼看明白:
{kind=link}
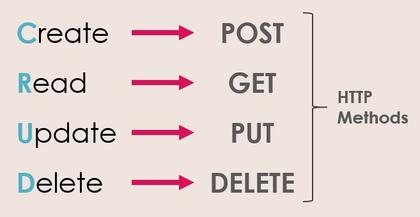
怎么能在简单和灵活性之间找到平衡呢?
第一,只能加,不能减
首先 API 只能增加,不能减少。减少,等于破坏别人的软件(依赖你 API 的软件)。
HTTP 规范中的 "referer" 头字段是单词 "referrer" 的著名拼写错误,但他们从未修正它,因为我们不能破坏用户空间。你不能因为现有设计有点别扭,就去修改一个 API。
第二,使用版本控制,但谨慎用
就是版本控制。但是这个要慎重用!!!
就是说:
GET /users
GET /users/1
POST /users
DELETE /users/1
变成(务必!!!)
GET /v1/users
GET /v1/users/1
POST /v1/users
DELETE /v1/users/1这样,v2 版本你就可以适当的发挥想象力一点了。
我不喜欢 API 版本管理。我认为充其量这只是个必要的恶,但终究是恶。用户会感到困惑——他们搜索 API 文档时,必须确保版本选择器与当前使用的版本匹配。而对维护者来说,这简直是噩梦。假如你有三十个 API 端点,每新增一个版本就要维护三十个新端点。很快你就会发现需要测试、调试和提供客户支持的 API 数量激增至数百个。
但是这会对文档生态造成灾难(文档难维护,资料难搜索,百害而一利)。所以,v1 这种版本前缀是要加的,但是除非巨大的更新,否则不要轻易使用。
最好使用长期有效的 API 秘钥
因为,使用短期凭证会加重后期使用和维护的复杂度。
就像现在的 AI 的 API ,清一色使用长期秘钥,多么舒服!
而且,其实你的用户,可能还是业余人员,略懂代码知识。要保持简单。
除非必要,少用幂等键
幂等键就是一个类似于「订单号」的概念。
每次请求,都多一个记录。但是不要滥用,除非必要,比如创建订单、发表评论、转账这类“每执行一次就多产生一份结果”的操作。
一般的操作,都不会多什么结果,比如读个评论等等。就不用。
速率限制得加
因为 API 调用速度远高于人工点击 ,尤其是 API 中的一些重要的常用的接口。
你应该为 API 设置速率限制,并对高消耗操作实施更严格的限制。 同时,保留对特定客户临时禁用 API 的能力也是明智之举,这样当后端系统真正承受巨大压力时,你可以减轻其负担。在 API 响应中包含速率限制元数据。X-Limit-Remaining 和 Retry-After 标头能为客户端提供所需信息,使其成为尊重 API 的消费者,并允许你设置比原本更严格的速率限制。
这个必须得加上速率限制。
因为很多事故和 bug 都来源于此。
使用游标分页,而不是页码分页
就像你看一些视频网站。
每页有 20 个电影,你到第 600 页了,然后你想单击,去第 601 页...
页码分页的 API 是这样,就是从第 1 部开始书,跳过前 600 * 20 个,去取第 12001 ~ 12020 部。很慢。
而 游标分页 是,记住第 600 页最后一部电影的 index ID (也就是 12000),然后如果请求下一页,直接请求大于 12000 的前 20 部。这样很快。
对于可能变得庞大的数据集,应始终使用基于游标的分页方式。尽管消费者更难理解这种机制,但当遇到扩展性问题时,你可能终究需要改用基于游标的分页,而实施这种变更的成本往往非常高。
不过,这种是仅限于庞大的数据集。一般的数据集,页码分页、偏移 这种常规方式就够了。
避免使用 GraphQL 风格的 API
API 风格很多,除了 REST API ,还有学生时代经典的 RPC 风格的 API ,还有 GraphQL 。
怎么理解呢?就跟拿菜单点菜一样,让用户自由构造任意查询 。感兴趣可以研究一下。
这种后端实现会难受的多,前端也不好维护。上手门槛有点高。