你跟 AI 对话后会发生什么?
时间:2026-7-3 01:19 作者:独元殇 分类: AI 与出海

今天水文一篇,把 AI 的一个旅程简单说说。其实就是一个流式传输,跟我们上网聊天、看视频一样。
你问了 AI 一个问题,然后被手机、电脑封装成数据包,穿越山川河流、江河湖海,甚至海底光缆,抵达数据中心(就是机房,里面都是电脑主机,叫服务器,只不过没有屏幕,而且不关机),分发给一个服务器,然后分配一块儿 GPU 给你处理,然后再回来。这个过程如此宏大,但是又如此的短暂,可能不到 1秒 ,甚至 1/10 秒。
每个计算中心里,GPU 有好几千块儿,甚至更多。
推理
我们平时数学上,物理上,是不是经常要处理一维、二维、或者三维空间这种计算?
然后数学和物理上,高深的领域又会有很多四维的计算。
更高深的有五维六维。不过在 AI 里,这种数学计算要考虑几千维。任何特征都要考虑,甚至语气、情绪,极度抽象。就这么的在算法里进行计算。
你发的那句给 AI 的问候,会在短时间里进行几十亿次的计算(相当费电,且需要高端的 GPU ,一块 GPU 可能几十万RMB呢!),然后预测下一个 token ,一个一个 token 进行预测。
这个 GPU 最开始是为打游戏设计的,游戏真的是人类生产力的推进者。如果不是因为电脑飞入寻常百姓家,也不会催生游戏的需求,催生人们对高水平显示效果的追求,也不会催生 GPU 显卡出现,也不会催生 AI 。
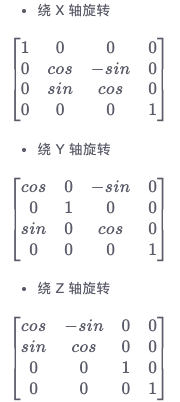
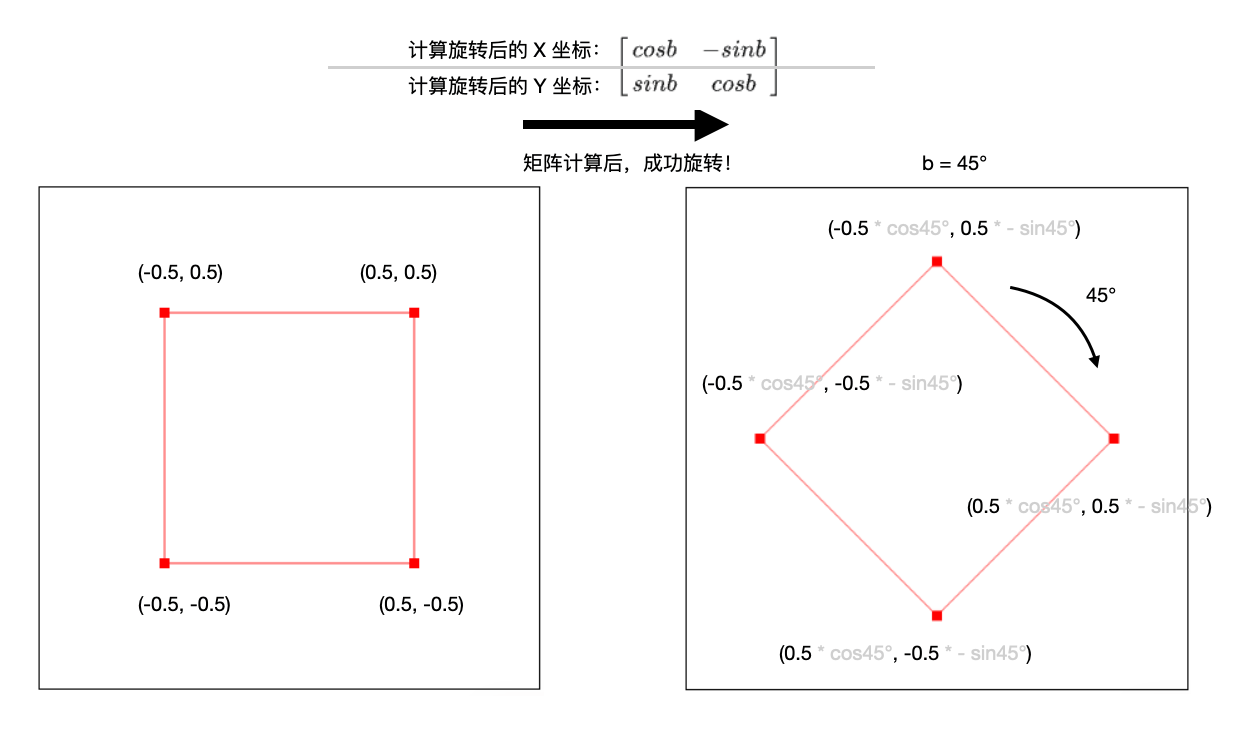
最开始 3D 世界,不就是里面会有大量的矩阵计算吗?每个像素点坐标需要乘以三角函数旋转计算,也就是矩阵乘法。
{kind=link}
{kind=link}
如果这个过程给 CPU 的话,就有点大材小用了,因为 GPU 算是一个一个算的,虽然每次算的快,但是止不住数量太巨多了。于是 GPU 出来,能同时算.... 比如当前比较高端的 英伟达 H100 SXM 能同时计算 27 万个计算(简单从乘法),每秒进行吓人的大约 3958 万亿次计算。
{kind=link}

AI 领域和 3D 游戏渲染很类似,也是进行矩阵乘法。而且 GPU 还得先把几百个 GB 的模型文件(权重文件)加载到 GPU 内存里,之后你的 提示词 进来,就能直接以数字的形式践行 矩阵乘法 计算,然后得出结果,再发出来给你。
如果你第一次调用 AI 去对话时,其实还没给你分配具体的某个 GPU ,而且可能 GPU 内存里还没有加载模型文件,通常延迟会有点高。再继续对话,就会很快了。如果你是本地部署的模型,那速度会一直很快。
其实,大部分时间差异源于共享 GPU 的排队时间,而非网络距离。因此,同一提示词可能因瞬时批处理压力而波动数秒。
而且吧,调用 LLM 并非单一操作。它还涉及身份验证、路由、提示构建、策略、模型行为、令牌核算、重试、日志记录和后处理。这些都会影响这个 API 的首次对话的时间耗时。
流式输出
大模型,输出是有速度的,不是一瞬间输出的。所以会跟你看直播一样,一个字一个字蹦出来。
小模型一般很快,400 token/s 甚至更高,主流的大模型会慢,一般都在 100 token/s 以内甚至更低。越大,就越慢。这也是为什么很多轻量级模型,后面会加上 flash , 比如 deepseek-v4-flash 。
目前主流的最快的大模型,是前几天谷歌发布的 Gemini 3.5 flash ,每秒高达 400 token !
因此,我们干一些比较简单的活儿时,用昂贵的大模型其实是不理性的,会干活慢。
不过有的时候,一些很雷同的提示词,会被系统缓存响应结果,再遇到会直接在缓存里用,能省点钱。
参考资料:
https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/
https://www.ccgxk.com/front-end/516.html
https://dev.to/dannwaneri/what-actually-happens-when-you-call-an-llm-api-28l6