ChatGPT 5.2 深度评测:OpenAI 最新模型功能更新与使用体验
时间:2025-12-12 16:45 作者:独元殇 分类: AI 与出海

目前,这个版本仍做不了考公的图形推测。
凌晨chatgpt5.2发布,虽然很多参数较gemini3.0还是有差距,但依然是一个值得去付费订阅的一个版本。
因为它主打的是【解决日常工作能力】
在它发表的白皮书,开头,不同往日的各种秀参数,而是直接亮明了这个版本的特点是牛马感极强的!它可以直接帮你干活了!
{kind=link}

开头三段,都在说这是个帮你工作型 AI
不过... 像各种模型热衷于的秀参数,那些都看看就行了,真厉不厉害,我们自己一测就知道了。而且那些参数什么,都迷惑性太强,像 deepseek 每个版本都说自己非常厉害,然后实际上还是感觉和之前的版本差距不大。
但这个 ChatGPT 5.2 的工作模式就不一样了,这个超级考验 AI 的情商、智商。因为和 AI 擅长的数学、编程不一样,这个很多时候不是开卷考试。
具体而言,根据人类专家评审的结果,GPT‑5.2 Thinking 在 GDPval 的知识型任务中,有 70.9% 的对比项目表现优于顶尖行业专业人士或与其持平。这些任务包括制作演示文稿、电子表格以及其他专业产出。GPT‑5.2 Thinking 的输出速度在 GDPval 任务中比专家快 11 倍以上,成本却不到其 1%。这表明,在有人类监督的情况下,GPT‑5.2 能有效辅助专业工作。(来自 Openai 官网)
上面说,GPT‑5.2 可以以极低的成本在不到一天的时间里,把从业多年顶级文科、专业金融从业者、电子办公专家一个星期的人物给昨晚,且大部分,输出质量优于人类专家。
有网友测评,让他制作一个业内的调查报表,生成速度要慢很多(因为它还要自己收集资料),一个 20 页左右的 PPT 要做一个小时,但最后的质量是相当高,约等于精英人类 3~4 天才能达到的程度。
目前 AI 已经把编程界搅的忧心忡忡了,现在已经正式要渗透电子办公界(对于体制内很友好,他们现在是彻底不用干活了,天天指挥 AI,而且不怕丢工作)。下一个估计就是容不得一点错的工业生产界了。到时候,就彻底实现全人类饭来张口了。
编程能力,白皮书上列举的这个案例还是惊艳我的;
{kind=link}
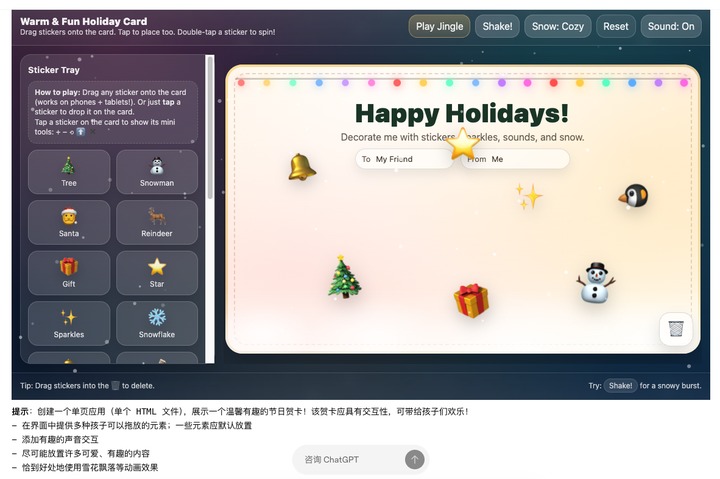
chatgpt5.2 生成的 节日贺卡生成器
我使用鼠标可以添加左边的元素到右边。
{kind=link}
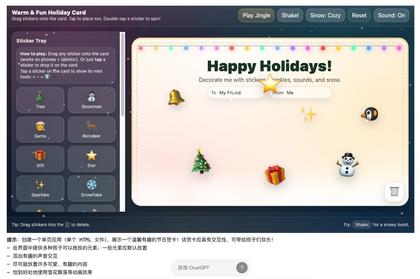
还可以对元素进行增删、旋转、置顶。还有精致的音效。
整体质量相当完美、精致。看着很昂贵。
GPT‑5.2 Thinking 的幻觉率低于 GPT‑5.1 Thinking。在一组来自 ChatGPT、已去标识化的查询中,含有错误的回答出现频率相对减少了 38%。对专业人士来说,这意味着在研究、写作、分析和决策支持等任务中,模型犯错更少,从而在日常知识型工作中更加可靠。
幻觉大大减少了,因为它会调用其他 ai 实时对输出进行求真。(相较 gemini 3.0 pro 的幻觉依然普遍,这个是 GPT5.2 为数不多的亮点)
这个对科研是好事。
{kind=link}

chatgpt 5.2 的版本
目前依然是三个版本。
轻量级、深度思考、专业级。
跑分就不看了,跑分不代表实际使用,很多模型会在跑分时用一些跑分小技巧的。deepseek 每次跑分都吊打 gemini ,那显然不切合我们的真实实际使用感受,同理 gemini 和 GPT 一样。
但我自我感觉,chatgpt 5.2pro 并没有逆转 Google 的局面,起码在生成时间上还是 Gemini3.0 pro 更厉害一点。但相较于 gemini 3.0 pro 付费版 动不动就明显降智,chatgpt 还是可以的。
现阶段,人类基本走入了一定程度的智商平权时代了。
现在 chatgpt 的路子还是对的,因为它之前一直是想走类似豆包那种路子,现在突然反应过来,AI 真正可贵的还是智商。
现在各大插件、ai 聚合都还没更新,但 cursor 、codex cli 已经接入了 chatgpt 5.2 了,大家可以试试看,比如哪一些考公图形推理题给它看看,看它怎么秒杀。
5.1做不了考公的图形推测,5.2 我这边还是卡壳,和 gemini3.0pro 一样。可能是因为美耶那边考公不做这个图推。