Deepseek V4 Pro 极高的缓存命中率很重要!
时间:2026-6-13 23:11 作者:独元殇 分类: 前端技术

我对 AI 的使用现在有两大分类。
如果是对话的话,一些对答案质量要求高的,使用 美国的 AI 。御三家都可以。
如果是 agent 给我干活的话(比如 codex 和 龙虾,而且干的是粗活儿),则会换上国产 AI 。由于我是个职业 SEO 和 SaaS 出海人,所以 agent 每天会帮我干很多很多事。不是我无脑爱国产,而是【大模型的缓存命中】,国产在这个领域做的真不错。
有个老外 Max Trivedi 说过:「代理工作流与大多数人类与 LLM 对话的一个关键区别在于:平均交互轮次数量要高得多」。
意思就是说,agent 干活儿时,会很频繁的重新阅读上下文,这个比原来最开始的 AI 对话框那种反反复复的几次对话要次数多得多。
如果是【缓存命中率】比较高的模型,则会很省钱!
最开始的模型,你和 AI 聊得越久,后面每问一次,成本和压力都会越来越大。因为它会全部重新读一遍。前面的内容会被反复读取,越聊越爆炸。而用了【缓存命中技术】,虽然内部也是重新读一遍,但是它会便宜给你计算,价格不一样。
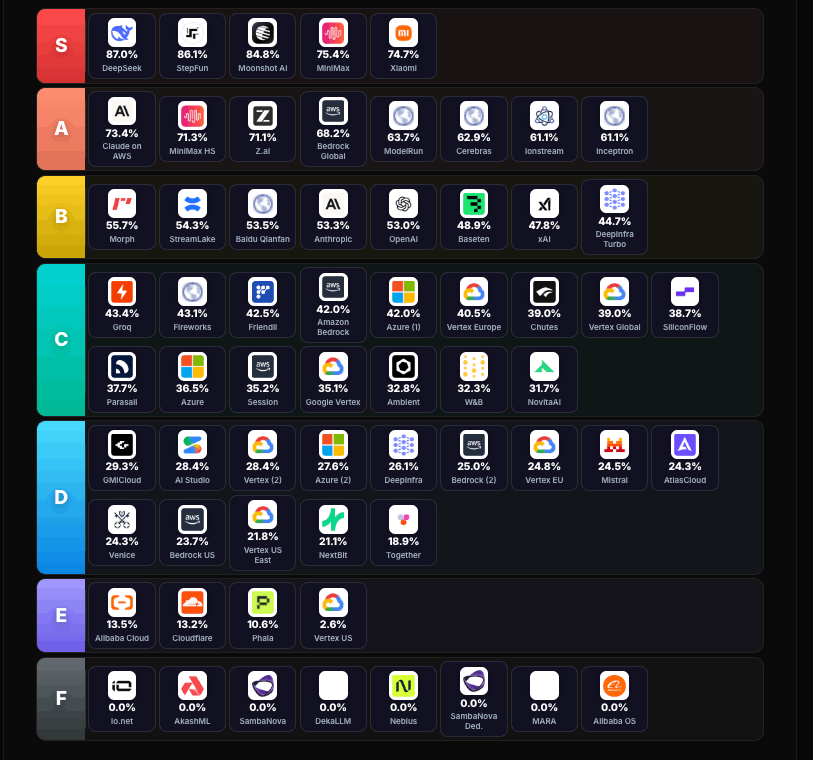
这个很重要。在 dirace 网,有人把不同缓存命中率的模型,分成了 7 档(这是通过观测,计算出来的):
{kind=link}
国产的 deepseek V4 以 87% 的惊人缓存率遥遥领先!
注意!这个【缓存命中率】主要是和模型提供商(托管商)有关,和模型关联小一点。
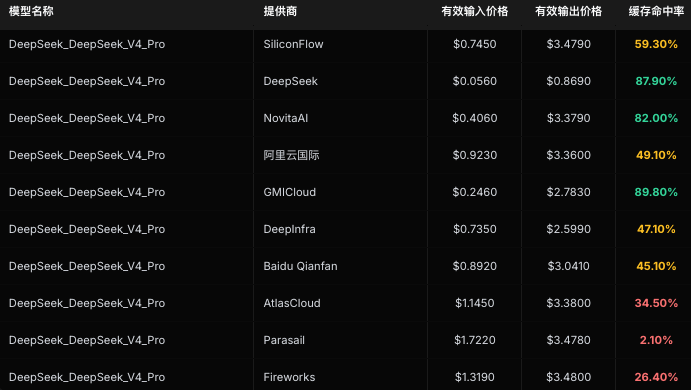
比如同样的 DeepSeek V4 Pro , 在官方,命中率是 87.90% ,但是在 Parasail 厂商则是只有 2.1%.... 即便是阿里云,也只有49.1% ,所以,要选择官方的 API 接口。
{kind=link}
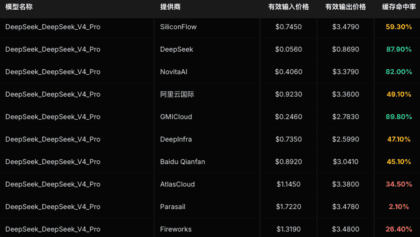
这也是为什么,我拼命让 deepseek 跑一整天,才花了 4 块多这种惊人的事情会发生。放在以前年初,不管什么主流的先进模型,一天起码得 25 元起步。有时候它内部不知道怎么样抖两下,50+ 都常见。
国产的都是 S 级:DeepSeek(87%)、 阶跃星辰(86.1%)、 月之暗面(84.8%)、MiniMax(75.4%) 和小米(74.7%)。
而美利坚的御三家呢?
去年的老模型就不说了,那时候 agent 还没成熟,人们意识不到这个的重要性。
比较新的模型,Opus 4.7 缓存命中率为 65.30% ,Gemini 3.1 Pro Preview 仅为 37.30% , GPT-5.4 是 74.9% 。
不过,更新的 GPT 5.5 也很高,是 93.2% ,但架不住单价非常昂贵啊。
综合来看 ,deepseek 单价低,而且缓存率极高。
其实今年顶级模型的缓存率都上来了,但是 deepseek 的单价远远比其他的模型低。
千问的 Qwen_Qwen36_35B_A3B 这个小模型,输出单价是 $1.1450 ,但是缓存率是 11.54% 。谷歌的 Google_Gemma_4_26B_A4B 输出单价是 $0.4150 ,但是缓存率只有 21.57% 。
这些可都是小模型!
而 deepseek 这种 1.6 亿参数的模型,输出单价 $0.8690 ,但是缓存率 87.90% !算下来,你可以比一个小于 千问3.6 中的任何模型的价格,使用一个 超级大参数的 模型。
$0.8690 是什么含金量。即便是国产的 glm 5.1 ,单价也是 $3.9590 ,GPT-54 则是 $15.1190 。
当然,为了利用好这个技术,最好我们多使用一些高度稳定固定的描述提示词,重复内容越多越好。
当然,顺便说一下,这个也很挑 agent 平台... 你要是使用 A 畜的 claude code ,它里面可能把 提示词 给你弄的乱七八糟,以至于会缓存为 0,不过最近貌似好多了,deepseek 对 CC 进行了优化:
{kind=link}
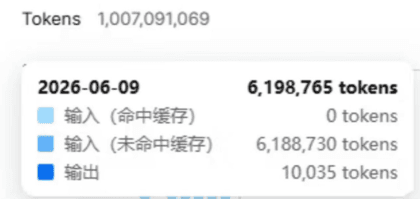
所以要多去 deepseek 账单页面看看,别吃亏了。国产的 agent 的缓存率都高一点,经常会达到 90%+ ,要多总结经验。
细活给充了会员的御三家干,大量的粗活,就让 deepseek 和 mimo 去做 ~
参考资料: