Unicode 与 UTF-8 的区别是什么?编码原理与乱码解决方案科普
时间:2025-12-14 00:56 作者:独元殇 分类: 前端技术

非技术人员不喜欢看代码,所以本文里面全是汉字和英文单词,没代码,就是一条线下去,给各位游客简单科普一下 Unicode。
你在电脑上看到的任何一处文本,都一定是根据某种编码而生成的。不过,这个在 2015 年以前,可能是 ASCII 、ISO-8859、GBK、koi8、euc、GBK..... 咱们中国以前有自研过 GBK。
到现在,已经基本完全被 UTF-8 大一统了,我们肉眼在电脑的任何地方看到的文本,99% 是 UTF-8 ,也就是 Unicode 标准的 8 bit 位编码格式。
Unicode 起源于 1988 年苹果公司和施乐公司,一直到 2004 年才被广泛使用。2015 年的时候基本就占领了全球,到现在,已经是编码之王了。
Unicode 又被称为万国码,全球通用。这段奋斗的历史,很像咱们中国古代的战国时期,那么多国家争夺王位,每种编码都有自己的逻辑自己的方式,尤其是汉语,当时 20 世纪末基本没几个支持,最后 Unicode 以其独特的编码方式,最终称王。我们简单了解一下这段历史,了解一下为什么!
先从 ASCII 讲起。计算机最初,要显示文本,就需要明确每个文本,要对应一个数字编码。毕竟电脑它只认识 0 和 1 。每个数字,就是一个比特位。
那么 7 位二进制,就能表示 128 个字符。
{kind=link}
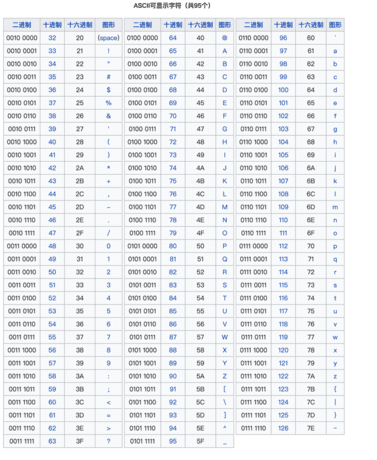
ASCII 码表
其中,除了 可显示的 95 个,还有很多不可显示的控制字符,比如换行等等。
对于当时主要使用英语的人来讲,足够了。
但计算机技术,传到欧洲后 法语的 é、德语的 ü 没地方放,那么他们又创造了 ISO-8859-1 标准,相当于扩展的 ASCII,扩展了 1 位,有 256 个的容量。这下全欧洲的字符就都包括了!
可亚洲呢?常用的中文汉字,就 3000 个,这种编码完全不行啊!于是自研了 GB2312 和台湾省的big5 等等。全世界都差不多,编码一片混乱。
世界常用的字符编码:
- Unicode (UTF-8)
- Unicode (UTF-16LE)
- Arabic (Windows-1256)
- Arabic (ISO-8859-6)
- Baltic (ISO-8859-4)
- Celtic (ISO-8859-14)
- Central European (ISO-8859-2)
- Chinese Simplified (GBK)
- Chinese Simplified (GB18030)
- Chinese Traditional (Big5)
- Cyrillic (ISO-8859-5)
- Cyrillic (Windows-1251)
- Cyrillic (KOI8-R)
- Japanese (Shift JIS)
- Japanese (EUC-JP)
- Korean (EUC-KR)
- Western (Macintosh)
- Western (Windows-1252)
编码混乱的问题是,如果你使用了错误的编码,打开一个文本文件,那么就会乱码!比如 � � �锟斤拷烫烫烫....
{kind=link}

一个乱码的网页
后来 1988 年苹果公司和施乐公司决定设计一个容量极大、能包容全部人类字符的字符编码。就是 Unicode 。
这个字符的创新是:不规定某个字符,它是存 2 bit 1 bit 还是几 bit,而是直接搞一个巨大的表格,每个字符都给它分配一个编号(学名 叫 码点)!
根据 Unicode 的标准,它的容量很大,是 110 万个。当然,我们目前已经很努力去塞了,包含所有的汉字生僻字,包含各种 emoji 表情、任何少数民族、任何国家的文字、甚至古老的埃及文字... 也才占用了 16 万个。也就 15% 左右。
足够我们用到天荒地老了~
目前 Unicode 有三种编码方案。UTF-8, UTF-16, UTF-32 。
首先,我们要知道 1字节 = 8 bit,就是比如 10110101 八个二进制数字。
UTF-32 就是所有字符占用 4 字节。4 × 8 = 32 嘛。
而 UTF-16 就是每个字符最少占用 2 字节。 utf-8就是每个字符最少占用 1 字节。
目前最流行的是 utf-8 。
但,这并不意味着 utf-8 每个字符都是 1 字节。它是一种可变长度的,就是:
- 英文和数字、符号等: 1 字节
- 欧洲等特殊字母: 2 字节
- 常用文字、常用汉字: 3 字节
- emoji 和生僻的文字: 4 字节
这样,你全英文,依然体积很小,有两个中文,也不至于很大..... 特别智能。
那么 UTF-32 存在的意义是什么?它会体积很大,但是计算机处理起来快啊!utf-8 体积最小,但处理起来慢一点点啊!UTF-16 就是一个妥协。基本没用。
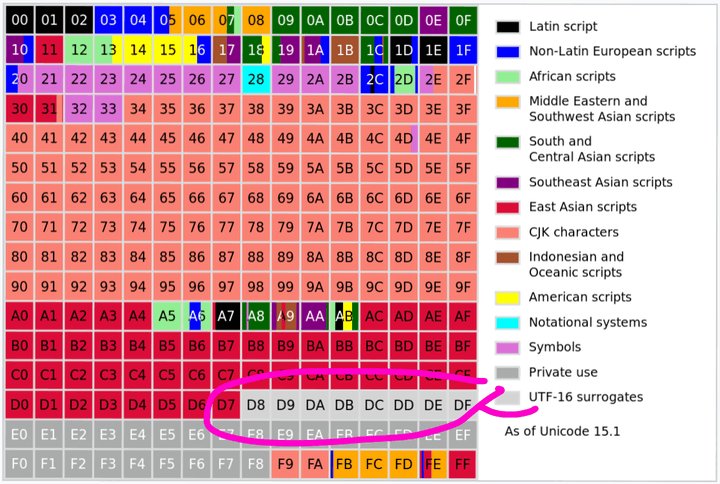
在 Unicode 内部,是这样分布的。
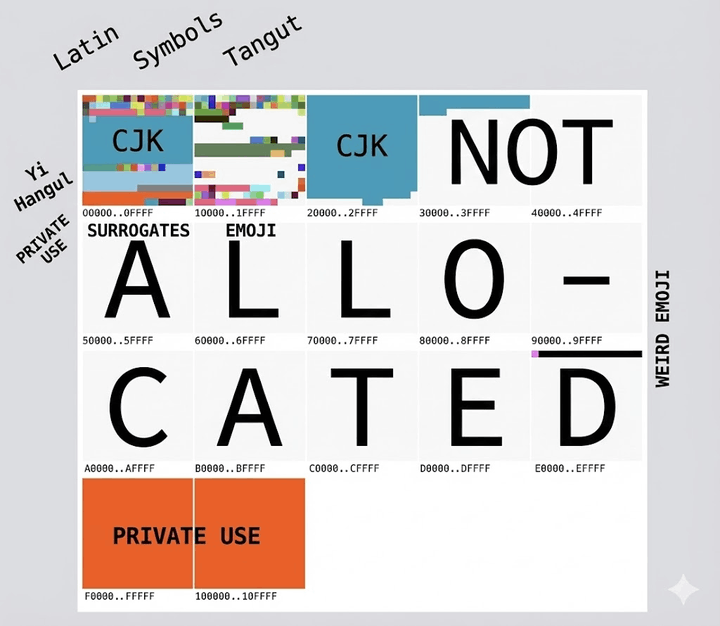{kind=link}
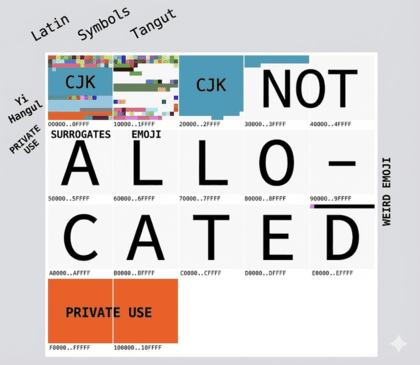
图源 tonsky me,Unicode 内部的分配
它将字符空间划分为 17 个“平面”(Plane),每个平面有 65536 个码点。
总容量高达约 110 万 !!!!
上面就是 17 个块儿。首先 0 号平面,就是最左上角那个,存放了所有的人类常用字符。比如 常用汉字、拉丁字母、希腊字母等。我们可以看到英文写着 拉丁字母(Latin)、符号(Symbols)、中日韩文字(CJK)、韩文(Hangul)....
{kind=link}
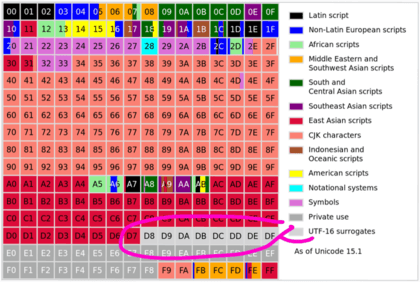
第一块常用文字块的放大图
后面 3 个是辅助的。是存放生僻的内容,比如 古埃及文字、生僻汉字、emoji 表情!英文注解写着 中国古代西夏文(Tangut)、生僻的中文(CJK)。
{kind=link}

emoji
emoji 最开始只是隔壁的日本人私下在电脑上玩的玩具,后来在 2010 年才被编入了 Unicode 。
在这 17 个块的其余部分,目前是未被使用的空白,以及最后两个红色的私有使用区(Private Use)。
Private Use 是 Unicode 标准永远不会去定义、去使用的。是专门给开发者预留的区域。
目前这个区域主要用于 icon fonts 。
我们在网页上看到的 很多按钮上的图标,就被定义在此:
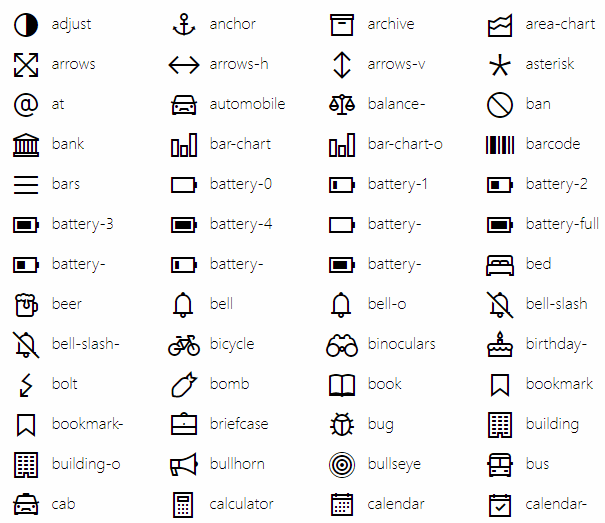{kind=link}

icon fonts 示例
这个是谁的网页谁负责,出了这个网页就不一定还显示成这个,你高兴,你也可以自己画一个,或者下载别人画好的。因为文字,在电脑里有专门的高效的算法去处理,所以icon fonts 就借用了文字的优点,会很省空间,体积小,显示快、显示质量好。
如果你是一个写网页的前端工程师、设计师,你肯定知道这个。
Unicode 是个什么东西,现在已经讲完了。
实际上,Unicode 内部的构造还是很复杂的。
{kind=link}

emoji 的复杂
比如某 emoji 表情 x 由 5 个代码点(U+1F926 U+1F3FB U+200D U+2642 U+FE0F) 组成。也就是,在人眼里,这是一个字符,但在 电脑眼里,这其实是 5 个字。它里面有很复杂的加减乘除法则以及一些为文字而妥协的内容。没办法,文字就是这么复杂。
但纵观全球,Unicode 的代表方案,UTF-8 ,目前是无任何缺点的,且最完美,也最实用的。