AI 技巧之为什么 上下文工程 比 提示词工程 重要很多?
时间:2026-3-11 21:41 作者:独元殇 分类: 开发相关

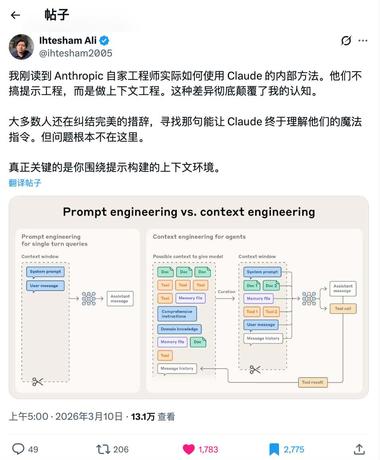
其实吧,在 claude 的公司 Anthropic 内部, 他们是不搞提示词工程,而是搞 上下文工程 的。在 2026 年,对于研究 AI 领域的应用、agent 等等的合格的工程师,注重 上下文工程 就是常识。
很简单,AI 也是有注意力的,AI 读的多又乱,脑子里也会产生噪音。
你可以理解为大模型是有注意力预算的,你必须得做出取舍,删除噪音!
只可惜现在市场上还是有大把人在卖课,教你怎么写提示词,哈哈。当然提示词也重要,保下限,上下文远远更重要,保上限。没有良好的上下文工程,AI 无法维护大型项目。
什么叫上下文工程?
很简单,就是设计好给 AI 阅读的内容。比如你让 AI 改代码,那你是把你项目几个 mb 的所有文件都扔给 AI ,还是精心整理本地文件,然后把最重要的内容扔给 AI ,显然后者肯定会很重要。就跟你给领导的报表一样。
之前我们,一直是在寻找怎么写完美的 prompt ,让 AI 给我们一个满意的答案。但显然,现在人发现了围绕提示词而构建的上下文环境,比提示词要重要很多。把重心放到提示词上,优点有很多。
比如说,用不着一口气把所有内容都吞下,而是按需取调取,我们如果监控过 claude code 的传输数据的话,我们会发现它这方面搞的很 6 ~ 。你会发现,在 bash 里到处都是 grep、head 、 tail 这种终端系统内置的分析命令,最后得到的最有用的结果经过多重整理后才会递给大模型,几乎从来不会一口气把一个几 mb 的或者说几千行代码的文件全吞进去。
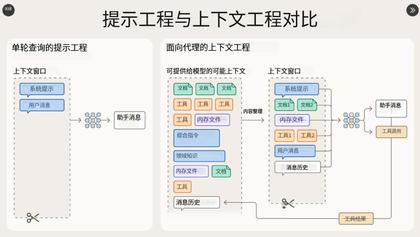
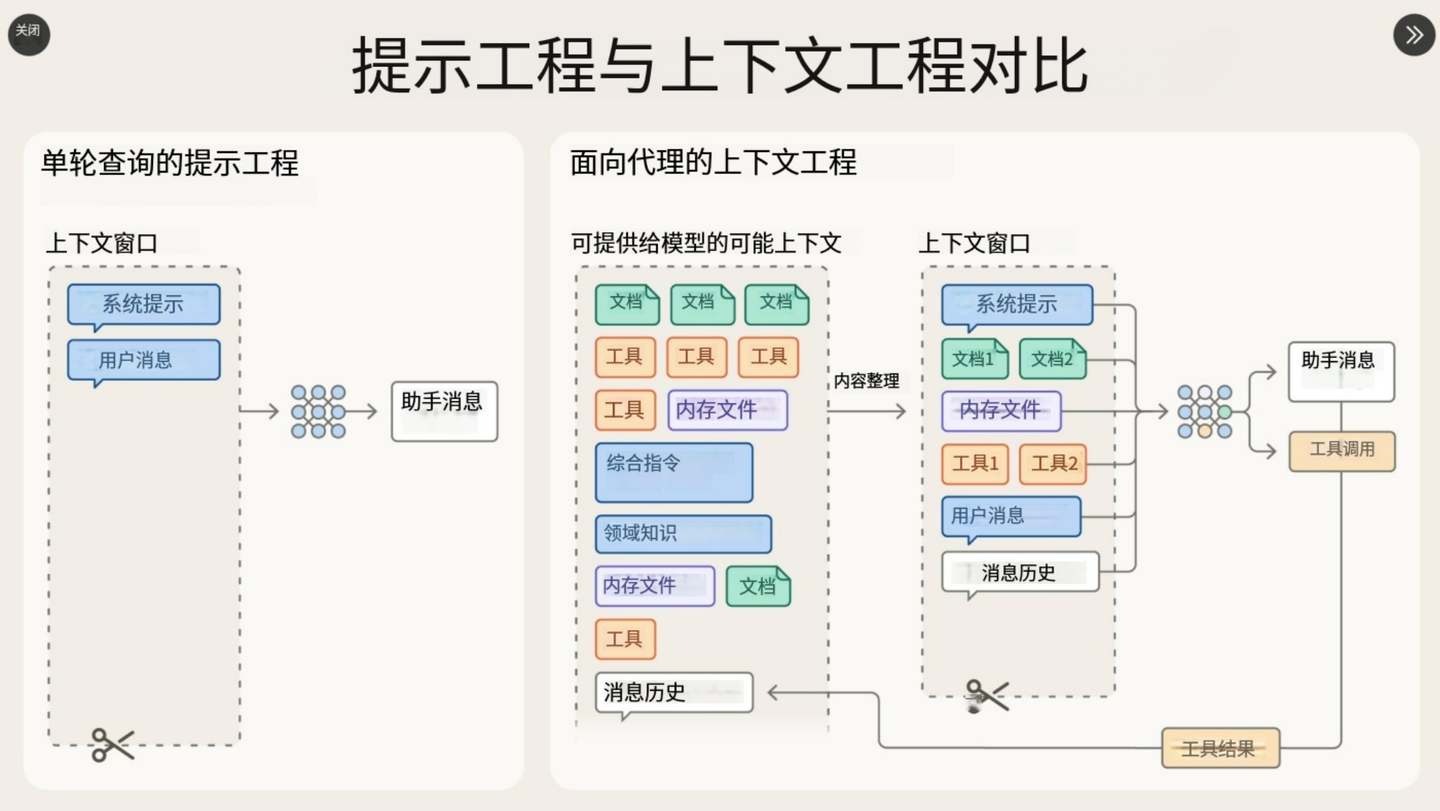
(上面 X 帖子的图的翻译)
而且 claude code 会自动对之前的内容压缩。如果你做过 AI 对话套壳 SaaS 站时,你会下意识每次都把之前的对话全部都发回,让对话越滚越多,信息膨胀。实际上 claude code 可能也会,但多多少少会智能压缩,只保留重要的内容(虽然吧,我的 claude code 也超级费 token 费钱,但是总比次次都一股脑把我所有相关东西扔过去要强百倍)。
还有就是很重要的 claude.md ,这个文件可以让我们持久性的记录重点,以及注意点。但其实 claude code 也会自己在 上下文 窗口之外撰写维护专用的笔记,记录重点、重要事项,而不是浪费 token 到很多无关细节上。关注点分离。
同时 claude code 为所有内容制定.md 格式的计划,更新变更,按日期/功能进行组织,为未来可能相关的功能准备文件,并在扩展功能时将该文件夹添加到上下文中。棒 ~
上下文容量越大,并不代表就越好
大语言模型,注意力是很宝贵的,并不是说你扔给它的所有内容,它都会一视同仁的看待,在它眼里,只有开头和结尾是重中之重,而越中间越差。另外,每增加一个词,注意力也会指数级衰减。如果不是搞上下文工程,而是只是一股脑扔内容,那么在 AI 的大脑里,其实也充满了噪音,从而导致一个很差的结果。
如果不搞上下文工程,只是一股脑将所有内容扔给 AI ,然后妄想精心打造一个牛哄哄的提示词,效果远远不如只精选最重要的部分作为上下文,精心设计递给 AI 的内容,得出的结果可靠。
作为一个出海 SaaS 人,我在给老外做 一些类似于 SaaS 应用时,也是搞精简上下文、结构化笔记、任务特定的代理。与将所有内容一股脑塞进一个提示相比,输出质量有天壤之别。
如果无休止地调整提示,肯定是不行的。
提示词没那么重要
真的,与其学习一大堆什么什么 PUA 大模型的稀奇咕嘎的技巧,还有什么【我会把你的结果给 chatgpt 看哦!】或者【我手上有着哈基米 🐱,如果你不好好回答,我就会打它一下】这种邪门歪道。
还不如闲着没事干,好好整理属于自己的知识库。模型的好坏,完全取决于你为它构建的思考世界。
其实就是实时检索,如果不是这个,也不是撑起来最近很火的把深圳闹的满街沸腾的 openclaw 龙虾机器人,龙虾处理的信息巨多,它一口气根本吃不下。"上下文腐化"现象会出现,我曾亲眼见过去年一些原始、古老的智能体,在处理一小时内原本能轻松完成的任务时,开始产生幻觉(现在你去一些在线 AI 对话器上,长时间使用,也会出现这种情况)。
只可惜,现在很多 AI 新手仍然在纠结「我应该怎么向模型提问」。也就是努力掌握提示词工程。当然,提示词也重要,但上下文设计好了,结果会更好。


{kind=link}
{kind=link}