都 2026 年了,数据库直接选 postgres 就行,不用 SQL 了
时间:2026-2-13 22:39 作者:独元殇 分类: 开发相关

都 2026 年了,在 99% 的情况下,选择 postgres 才对!
我们在项目开发里,会遇到各种不同项目类型的解决方案,比如 缓存 Redis 、存大量文档 MongoDB ,消息队列就是 kafka ,搜索就是 elasticsearch ,向量数据库 就是 pinecone ,还有很多很多。
这些都是专用数据库!
但是..... 但是有个问题,你每类数据库的 查询语言、维护策略都不一样,甚至你还得每天轮流看 7 个仪表盘。《数据库泛滥》《数据库蔓延》!
而解决这个事儿, postgres 就是最优解!
尤其是现在这个 AI 时代。
我是搞 独立站出海 SaaS 的,现在严重依赖 AI 来给我写代码。
如果还是以前那样,很难快速启动一个万人用户规模的项目 demo 。当然,也不是很难,就是麻烦,配置又慢又麻烦,完后还得再挨个儿卸载。出了问题更是头疼!
当然,这些都是专业的专用数据库,不错,可是我觉得它们提升了很多的复杂性。
其实 99.99% 的项目根本用不到这么牛的东西。
这个时候直接来个 postgres 就 OK 了。全部都搞定了!
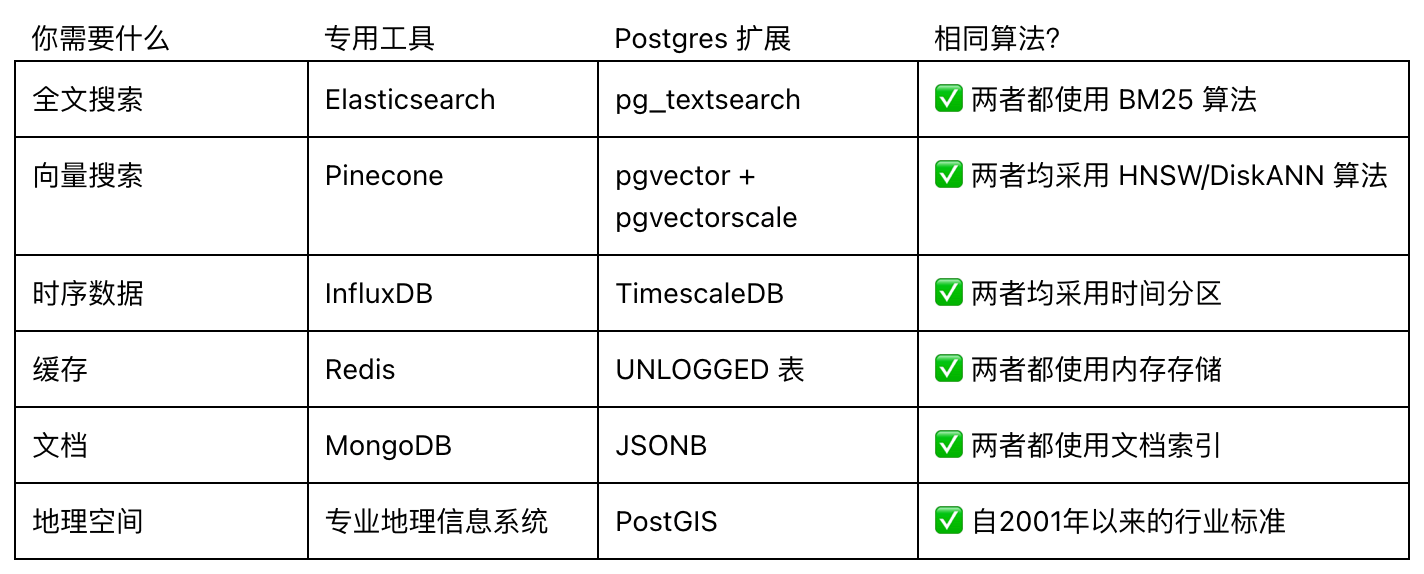
外网的大佬 Raja Rao DV 说:Postgres 扩展使用的算法与专用数据库相同甚至更优(在许多情况下)。
比如这个对比:
{kind=link}
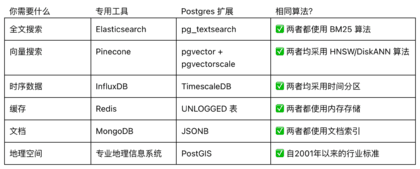
很多性能都媲美专用数据库!(这些插件的平均寿命是 10 年左右,已经具备多年的生产环境稳定性了)
只需要这样就行了:
-- 全文搜索 BM25
CREATE EXTENSION pg_textsearch;
-- 向量 for AI
CREATE EXTENSION vector;
CREATE EXTENSION vectorscale;
-- RAG 应用需要的流水线
CREATE EXTENSION ai;
-- 时间
CREATE EXTENSION timescaledb;
-- 队列管理
CREATE EXTENSION pgmq;
-- 日程表
CREATE EXTENSION pg_cron;
-- GIS
CREATE EXTENSION postgis;比如说 pg_textsearch 这个插件,你安装后,就可以获得和 Elasticsearch 完全相同的 BM25 算法!而且只需要使用 SQL 就行!
可能有差距,但很小,可以直接忽略,但带来的好处是 构建速度、维护方便性,都大幅度提升了!故障也容易排除了。
而且 Reddit、Instagram、Discord、Netflix、Spotify、Uber 这些海外大企业也都在用 posygreSQL !
大佬 Raja Rao 整理了一些安装代码,在 https://www.tigerdata.com/blog/its-2026-just-use-postgres 这篇文章里,我觉得非常有用!
下面是摘录:
全文搜索(替代 Elasticsearch)
扩展: pg_textsearch(真正的 BM25 排名算法)
您正在替换的是:
- Elasticsearch: 独立的 JVM 集群、复杂的映射、同步管道、Java 堆调优
- Solr: 情况类似,只是包装不同
- Algolia: 每 1000 次搜索收费 1 美元,依赖外部 API
您将获得: 与 Elasticsearch 完全相同的 BM25 算法 ,直接在 Postgres 中运行。
-- Create table
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title TEXT,
content TEXT
);
-- Create BM25 index
CREATE INDEX idx_articles_bm25 ON articles USING bm25(content)
WITH (text_config = 'english');
-- Search with BM25 scoring
SELECT title, -(content <@> 'database optimization') as score
FROM articles
ORDER BY content <@> 'database optimization'
LIMIT 10;混合搜索:BM25 + 向量,一查询搞定:
SELECT
title,
-(content <@> 'database optimization') as bm25_score,
embedding <=> query_embedding as vector_distance,
0.7 * (-(content <@> 'database optimization')) +
0.3 * (1 - (embedding <=> query_embedding)) as hybrid_score
FROM articles
ORDER BY hybrid_score DESC
LIMIT 10;这是 Elasticsearch 需要单独插件才能实现的功能。而在 Postgres 中,只需使用 SQL 即可。
向量搜索(替代 Pinecone)
扩展功能: pgvector + pgvectorscale
你所替换的:
- Pinecone: 每月最低 70 美元,独立的基础设施,数据同步令人头疼
- Qdrant、Milvus、Weaviate: 需要管理更多基础设施
你所获得的:pgvectorscale 采用 DiskANN 算法 (来自微软研究院),在 99%召回率下,实现了 p95 延迟降低 28 倍 和 吞吐量提升 16 倍 的性能,优于 Pinecone。
-- Enable extensions
CREATE EXTENSION vector;
CREATE EXTENSION vectorscale CASCADE;
-- Table with embeddings
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(1536)
);
-- High-performance index (DiskANN)
CREATE INDEX idx_docs_embedding ON documents USING diskann(embedding);
-- Find similar documents
SELECT content, embedding <=> '[0.1, 0.2, ...]'::vector as distance
FROM documents
ORDER BY embedding <=> '[0.1, 0.2, ...]'::vector
LIMIT 10;使用 pgai 自动同步嵌入:
SELECT ai.create_vectorizer(
'documents'::regclass,
loading => ai.loading_column(column_name=>'content'),
embedding => ai.embedding_openai(model=>'text-embedding-3-small', dimensions=>'1536')
);现在每次 INSERT/UPDATE 操作都会自动重新生成嵌入向量。无需同步作业。杜绝数据漂移。告别凌晨三点的告警通知。
时序数据库(替代 InfluxDB)
扩展组件: TimescaleDB(GitHub 星标数 21K+)
您将替代的是:
- InfluxDB: 独立数据库系统,采用 Flux 查询语言或非原生 SQL 支持,SQL 功能有限
- Prometheus: 擅长处理指标数据,但不适合存储应用数据
您将获得:自动时间分区、高达 90%的压缩率、持续聚合功能,以及完整的 SQL 支持。
-- Enable TimescaleDB
CREATE EXTENSION timescaledb;
-- Create table
CREATE TABLE metrics (
time TIMESTAMPTZ NOT NULL,
device_id TEXT,
temperature DOUBLE PRECISION
);
-- Convert to hypertable
SELECT create_hypertable('metrics', 'time');
-- Query with time buckets
SELECT time_bucket('1 hour', time) as hour,
AVG(temperature)
FROM metrics
WHERE time > NOW() - INTERVAL '24 hours'
GROUP BY hour;
-- Auto-delete old data
SELECT add_retention_policy('metrics', INTERVAL '30 days');
-- Compression (90% storage reduction)
ALTER TABLE metrics SET (timescaledb.compress);
SELECT add_compression_policy('metrics', INTERVAL '7 days');缓存(替代 Redis)
功能特性: 非日志表 + JSONB
-- UNLOGGED = no WAL overhead, faster writes
CREATE UNLOGGED TABLE cache (
key TEXT PRIMARY KEY,
value JSONB,
expires_at TIMESTAMPTZ
);
-- Set with expiration
INSERT INTO cache (key, value, expires_at)
VALUES ('user:123', '{"name": "Alice"}', NOW() + INTERVAL '1 hour')
ON CONFLICT (key) DO UPDATE SET value = EXCLUDED.value;
-- Get
SELECT value FROM cache WHERE key = 'user:123' AND expires_at > NOW();
-- Cleanup (schedule with pg_cron)
DELETE FROM cache WHERE expires_at < NOW();消息队列(替代 Kafka)
扩展组件:pgmq
CREATE EXTENSION pgmq;
SELECT pgmq.create('my_queue');
-- Send
SELECT pgmq.send('my_queue', '{"event": "signup", "user_id": 123}');
-- Receive (with visibility timeout)
SELECT * FROM pgmq.read('my_queue', 30, 5);
-- Delete after processing
SELECT pgmq.delete('my_queue', msg_id);或者原生的 SKIP LOCKED 模式:
CREATE TABLE jobs (
id SERIAL PRIMARY KEY,
payload JSONB,
status TEXT DEFAULT 'pending'
);
-- Worker claims job atomically
UPDATE jobs SET status = 'processing'
WHERE id = (
SELECT id FROM jobs WHERE status = 'pending'
FOR UPDATE SKIP LOCKED LIMIT 1
) RETURNING *;文档(替代 MongoDB)
功能特性: 原生 JSONB
CREATE TABLE users (
id SERIAL PRIMARY KEY,
data JSONB
);
-- Insert nested document
INSERT INTO users (data) VALUES ('{
"name": "Alice",
"profile": {"bio": "Developer", "links": ["github.com/alice"]}
}');
-- Query nested fields
SELECT data->>'name', data->'profile'->>'bio'
FROM users
WHERE data->'profile'->>'bio' LIKE '%Developer%';
-- Index JSON fields
CREATE INDEX idx_users_email ON users ((data->>'email'));地理空间(替代专业地理信息系统)
扩展功能:PostGIS
CREATE EXTENSION postgis;
CREATE TABLE stores (
id SERIAL PRIMARY KEY,
name TEXT,
location GEOGRAPHY(POINT, 4326)
);
-- Find stores within 5km
SELECT name, ST_Distance(location, ST_MakePoint(-122.4, 37.78)::geography) as meters
FROM stores
WHERE ST_DWithin(location, ST_MakePoint(-122.4, 37.78)::geography, 5000);定时任务(替代 Cron)
扩展功能: pg_cron
CREATE EXTENSION pg_cron;
-- Run every hour
SELECT cron.schedule('cleanup', '0 * * * *',
$$DELETE FROM cache WHERE expires_at < NOW()$$);
-- Nightly rollup
SELECT cron.schedule('rollup', '0 2 * * *',
$$REFRESH MATERIALIZED VIEW CONCURRENTLY daily_stats$$);混合搜索(BM25 + 向量)
对于 AI 应用,您通常需要同时具备关键词搜索和语义搜索功能:
-- Reciprocal Rank Fusion: combine keyword + semantic search
WITH bm25 AS (
SELECT id, ROW_NUMBER() OVER (ORDER BY content <@> $1) as rank
FROM documents LIMIT 20
),
vectors AS (
SELECT id, ROW_NUMBER() OVER (ORDER BY embedding <=> $2) as rank
FROM documents LIMIT 20
)
SELECT d.*,
1.0/(60 + COALESCE(b.rank, 1000)) +
1.0/(60 + COALESCE(v.rank, 1000)) as score
FROM documents d
LEFT JOIN bm25 b ON d.id = b.id
LEFT JOIN vectors v ON d.id = v.id
WHERE b.id IS NOT NULL OR v.id IS NOT NULL
ORDER BY score DESC LIMIT 10;若用 Elasticsearch + Pinecone 实现此功能,您将需要两次 API 调用、结果合并、故障处理,并承受双倍延迟。
在 Postgres 中:一次查询,一个事务,一个结果。
模糊搜索(容错拼写)
扩展功能: pg_trgm(内置于 Postgres)
CREATE EXTENSION pg_trgm;
CREATE INDEX idx_name_trgm ON products USING GIN (name gin_trgm_ops);
-- Finds "PostgreSQL" even with typo
SELECT name FROM products
WHERE name % 'posgresql'
ORDER BY similarity(name, 'posgresql') DESC;图遍历(替代图数据库)
功能: 递归 CTE
-- Find all reports under a manager (org chart)
WITH RECURSIVE org_tree AS (
SELECT id, name, manager_id, 1 as depth
FROM employees WHERE id = 42
UNION ALL
SELECT e.id, e.name, e.manager_id, t.depth + 1
FROM employees e
JOIN org_tree t ON e.manager_id = t.id
WHERE t.depth < 10
)
SELECT * FROM org_tree;