从 0 用户到 1000 万用户,服务架构都选择什么技术?
时间:2026-2-10 01:19 作者:独元殇 分类: 开发相关

问题里的系统设计是一个泛概念。我这边以一个软件里的系统设计的来说。也就是系统架构。
最近拜读了亚马逊前工程师 Pratap Singh 写的 0 ~ 3, 000, 000 用户的系统都要怎么设计的文章,他把不同阶段、不同用户量级的系统,分为 7 个阶段。
原文过于严肃和长,下面是我做的笔记。
其实我们一直在经历重复,初创系统到大型科技公司,这些系统在成长过程里会不断的重复一些相似的阶段。
今天为大家揭秘一下,一个系统是怎么从简单到复杂的?
首先是 100 个用户阶段
用户 100 的单服务器阶段(1)
初创公司刚起步,任务是 MVP (最小可行产品),不要过早优化!
如果过早优化,则会浪费大量的时间、金钱在一些毫无意义的问题上。
架构很简单,就是说有内容放到 单台服务器 上,比如 Web 服务、数据库、后端业务程序等等。
比如 Instagram 就是这样搞的。
关键点就是,无需为了未来的巨大流量,而预先设计一个庞大的复杂的系统。这个是关键点,尤其是大厂待久的人,开项目,就搞的很复杂。都是一些没有意义的复杂。
不要明知故犯,忍住这种冲动。
只有当业务转起来了,服务器有点力不从心时(一般就是数据库遇到高峰流量,变慢了),再开始下一步!
用户 1000 的分离数据库阶段(2)
为什么分离数据库呢?
因为数据库遇到一个繁重的查询时,会让整个服务器卡顿(争夺 CPU)。因此第二阶段,就是 数据库 与 应用程序 分离。资源隔离嘛!
这样,两者就不争夺 CPU 了,都使用各自 100% 的CPU 资源。
另外,也可以独立升级、也有 部署到私有网络里不暴露在互联网里的 安全性。
当然,没必要买独立的 服务器 ,现在市场有很多现成的 数据库 服务,比如对独立开发者 和 初创公司友好的 Supabase !
除了性价比高,还能自动备份、告警、监控、副本、故障转移.... 省时间让我们做新东西。
当然,Amazon RDS、Google Cloud SQL、Azure Database 也不错。
这个时候有一个新的知识点,连接池!
(连接池就是提前保持少量数据库连接不关闭,这样避免频繁建连和断连,省内存、省 CPU,也减少延迟)
有三种模式。
会话池:兼容性好,但效率低,每个 客户端 对应一个池。
事务池(推荐):最均衡的模式,每个事务结束后,连接返回池中。
语句池:效率最高,但兼容性差。每条语句执行后返回池中。
当然,还有网络延迟要考虑一下。一般 1000 用户量,即便它延迟有个几毫秒的言辞,也是忽略不计的。
用户 10000 的负载均衡器和水平扩展(3)
在第二阶段里,有一个大问题:虽然 应用服务器 和 数据库 已经分离了,但用户数量已经上万了,应用服务器 宕机 了(也就是单点故障)怎么办?
宕机不一定是程序出错,也有可能是流量突然太大。
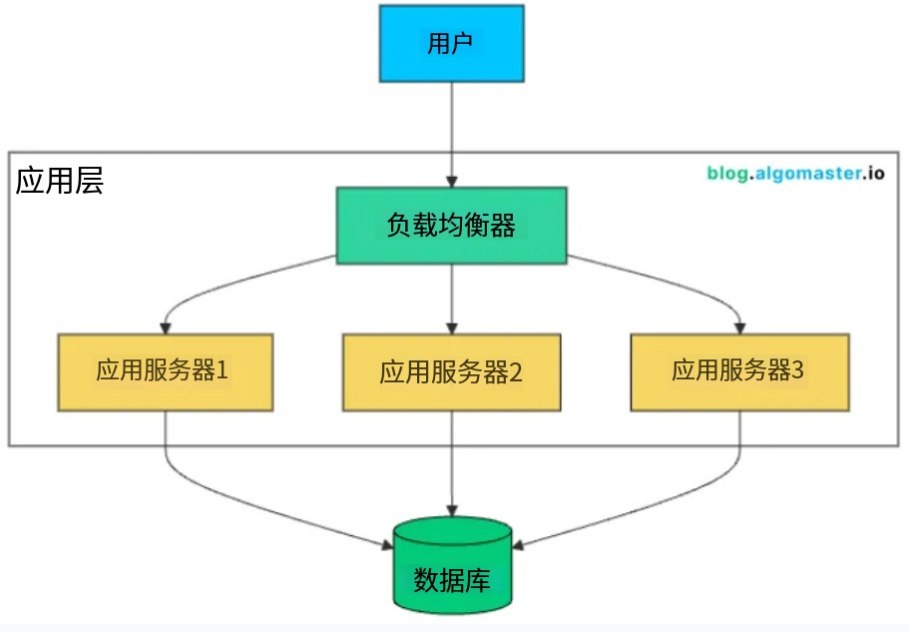
因此我们设立多个服务器,比如 三个 ,然后在用户和服务器之间,设计一个 负载均衡器 ,然后负责分发传入请求。(毕竟 服务器 干的活 基本都一样嘛)
为什么不使用更大的服务器呢?因为服务器的定价不是线性的,高一点配置,可能成本上升好几倍。
{kind=link}
如果一台服务器宕机了,那么会被检测到,然后会自动将流量切换到健康的服务器。用户那边是毫无感觉的。
一般这个 负载均衡器 是在两种层级运行的。
第一种是在 传输层 ,也就是 IP 和端口、路由器这边,速度极快,但不检查 HTTP 头部信息。
第二种是在 应用层 (推荐) ,也就是服务器上的一个软件,它有一定开销,但由于能查看 HTTP 头部,因此更灵活。
用户 10 万的缓存+副本阶段+CDN(4)
现在是有 10 万用户了,应用服务器已经不是瓶颈,但数据库成瓶颈了!
每个请求都访问同一个数据库,数据库撑不住了。
于是引入了 缓存、读副本、内容分发网络。
一般而言,80% 的请求访问 20% 的数据。于是我们的缓存,就把那些频繁访问的数据储存在内存里。
最常见的缓存模式是 延迟加载 模式(旁路缓存)。
应用程序先检查 缓存,发现有,就返回。
如果没有,再去查数据库,紧接着将结果缓存,然后才返回结果。
比如 Redis 和 Memcached 就是这样。
当然,也不是每个对象都适合缓存。
比如频繁变动的信息和一些大体积但用处不大的信息。
但这个时候,会碰到一个计算机科学难题,也就是【如果底层数据变了,那缓存数据就过时了,怎么办?】
因此,有一个 事件过期 策略, TTL 过期,比如 5 分钟后缓存过期。
还有一个概念,是副本。
数据库,分为 主数据库(处理写入)、副本数据库(以异步方式同步复制,只读)。
这样,主数据库,被写入数据,然后在几毫秒内复制到多个副本上,之后再加上缓存机制,整体吞吐量提高不少!
由于异步复制有几毫秒、几秒的延迟,但大多数应用都不在意这几毫秒,朋友发的知乎帖子,你晚 5 秒看到,没啥事。直播间的留言,博主即便 10 秒后才看到,也不是大事。
但我们还会遇到【读写一致性】。
什么意思呢?比如你更新了个人资料,但马上刷新,却发现还是旧数据。
怎么办?一般我们写入后,这几秒钟,「开通 VIP 权限」哈哈,让路由,直接允许从主数据库来读取。
当然,每次写入,都写上时间戳,对于刚更新的数据,都从主数据库读取。
至于 CDN 这个大家都见得多了,就是应用里的大型静态资源,比如图片视频,就单独设立一个专业的服务器,节省你 应用服务器 的带宽和 CPU 。而且全球都有节点,还帮助加速你网站。
各大服务厂商基本都有 CDN 服务。
用户 50 万的自动扩容+无状态阶段(5)
在上一阶段,大部分系统都能稳定应对大用户量服务了。
可是,用户规模超过 50 万,流量就会很难预测,比如爆款帖子,巨大流量让你的网站被搞宕机了。
这个时候你应该考虑服务 无状态化 了。
就是服务器能自由增减,但是不丢失数据。
只有这样,你才能实现自动扩容。
一般,我们采用基于 CPU 的扩容方案,也就是我们在很多云厂商后台看到的 实例数 。
最小实例数:也即是最小的服务数量,至少应为 2 个,如果一个宕了,另一个能接住。
冷却期:移除资源比扩容时间长,风险更高。防止系统抖动,也就是快速缩容、扩容。
实例预热,新服务器在开机、运行、准备就绪前,是不计入实例数的。
积极扩容、保守缩容。也就是快速扩张服务器,但是缩容时慢一点。
另外,为了保证 无状态 ,我们一般使用 JWT (JSON Web Tokens)这种基于令牌识别用户的方式,这样我们就无需每个请求都查询会话了。
这个令牌里,包含 用户 ID 、角色、过期时间,任何服务器看到,都能无缝验证,这样就实现无状态了。
当然,为了防止被盗刷,我们有两种令牌,一种是短期访问 15 分钟、一种是 7 天刷新令牌。
现在的瓶颈,就是服务器的写入了!
用户 100 万的分片+微服务+消息队列(6)
在 100万 用户 体量下,很容易导致 主服务器 写入宕机。
于是有了分片:数据库分片!
就是把主数据库给拆分了,把表按规则,拆分成很多表,每个分片只管一小部分数据。
比如不同时间范围、ID 范围、订单号等等对应不同的数据库分片。
每次请求进来,都是先进行定位,定位到某个分片上,然后再写入。
但要注意,分片后的数据库,调整起来代价巨大,因此,轻易不可分片!一般是一个久经考验的稳定了的表,再进行分片。
分片有算法,最常用的是 【一致性哈希】法,就是把键全放到一个圆盘上,当你添加一个新的分片时,只有与其位置相邻的键会移动,而不是所有键。这意味着添加第四个分片时,大约只有 25%的数据需要移动,而不是约 75%。
由于分片会大大增加复杂度,所以只有 优化查询、垂直扩展、只读副本、缓存机制、连接池都无法再优化时,物理无法解决瓶颈,才进行分片。
而 微服务,则简单很多,就是你的服务,不是一个整体,而是一大堆模块,相互独立。
这样你可以实现,比如:搜索功能需10台服务器,个人资料浏览仅需2台,这种。
甚至每个服务,都有自己的独立数据库。
而且方便更新、修理、开发、优化。
而这些 微服务 之间的交互,肯定得是异步的,就是消息队列。
消息队列,不是普通的异步请求,它的最大的优点是,当消息无法送达时,不会丢掉,而是储存起来,等对方服务器恢复正常时,再递送。
消息队列,是把 发送请求 这个事,做的更专业了,它还能均衡,对于不同的任务采取不同的优先级,急迫的任务,比如发帖,就是快速执行递送,而新闻推送,则可能延迟一些。
用户 1000 万的多区域部署与高级架构模式(7)
千万级别的用户,一般都是跨国企业了。
那么新的挑战就来了,不同国家间的高延迟、数据中心故障、不同地区的数据储存法律等等。
这个时候,就不能是单点服务器了。
因此就要考虑 多区域部署 和 容灾恢复 了。
中国用户访问中国的服务器,日本访问日本的,美国访问美国的,延迟降低。
数据也同步部署到多个地方,主区故障,分区瞬间接管。
现在疑问来了?!
既然很多主数据库,那么两个区域的人都去写入同一个数据库,不久乱套了。
这便是 CAP 定理了。
也就是 一致性 、可用性、分区容错性 三者只能满足其二。
比如金融系统,一般会在全球同步数据时,暂停服务。
而普通社交平台更倾向于 全球各地数据可以不一样,允许有延迟,但始终可读。
而仍有一些系统,很少见,都在本地运行读写,不考虑全球分区(即便真的会全球同步数据)。
一般我们使用第二种,也就是 可用 + 分区容错。
还有 CQRS,也就是【增删改】是一套系统规范、【查】是另一套系统规范。
比如 写操作使用 PostgreSQL,读操作使用 Elasticsearch ,两者都能获得较好的性能。
后记
这上面的方案,能维持住 1000 万用户量级了。
而对于一些很优秀的千万用户级以上的企业,则需要定制基础设施了。
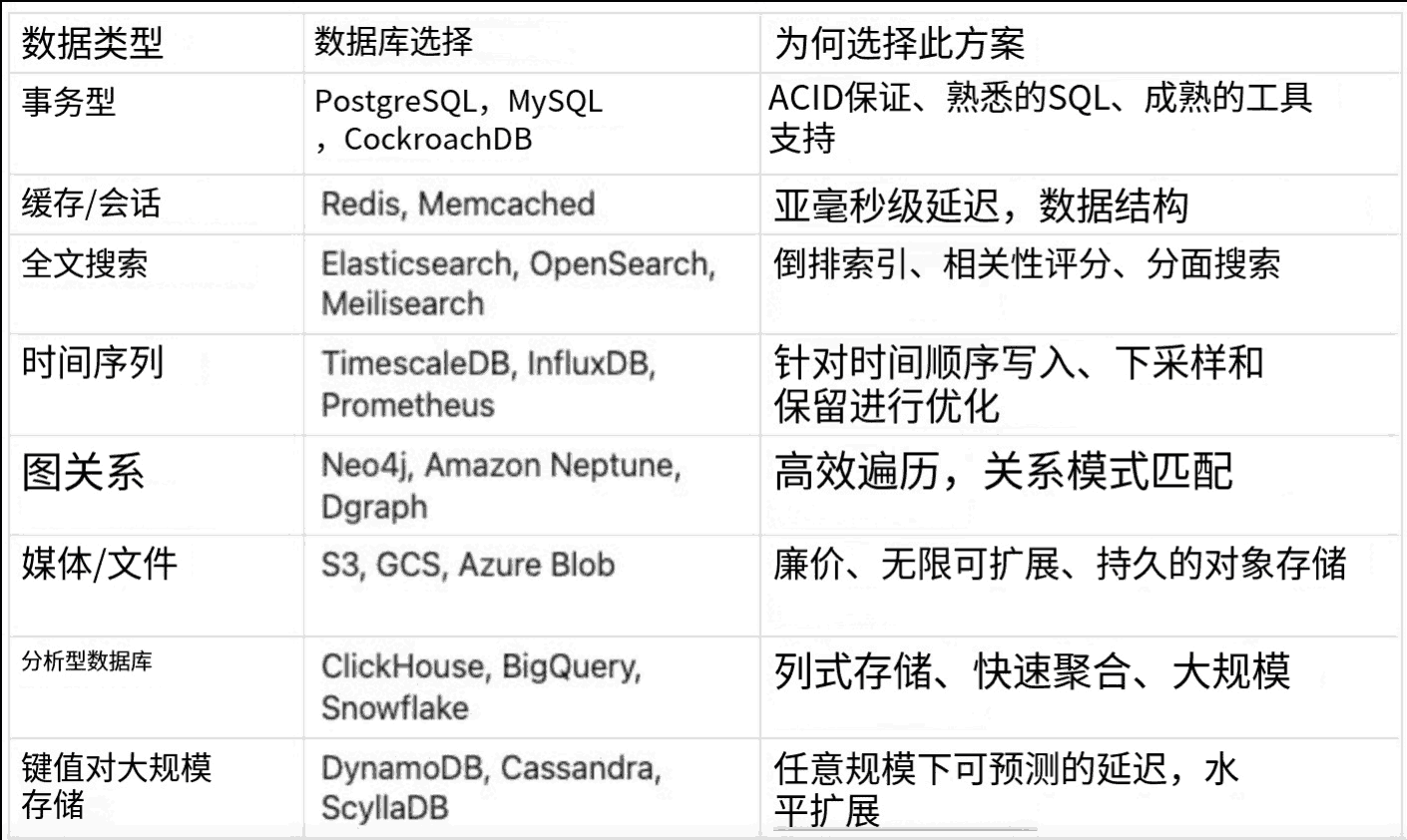
比如不同的数据,选择不同的数据库:
{kind=link}
还有边缘计算,比如咱们很熟悉的Cloudflare Workers:在 250 多个边缘节点运行 JavaScript/WASM 。实现全球到处都是自己的服务器。边缘节点具备足够的计算能力来处理业务逻辑。