保护私人数据护城河,促进 AI 回流的 RAG 检索增强生成是什么?1000 字说清!
时间:2026-2-19 00:17 作者:独元殇 分类: AI 与出海

有意义,是保护私有知识产权不被 AI 白嫖的护城河,而且也会让 AI 不得不受到阻碍,然后让客户流量重回你站。
(RAG 其实就是基于私人数据库的 AI ,就类似于在线客服。主要用于检索信息,让结果更加准)
但是更长的 LLM 上下文它每次对话,都会将全部的上文再重复投喂一遍,浪费 token 。而 RAG 则只要调好了,实现的效果甚至比巨长的 LLM 上下文还要好!因为上下文,它毕竟还是会分配权重的(无限上下文,肯定不可能真的无限,绝对有侧重点,重头尾,轻中间),而 RAG 则是一种全文检索技术。
今天晚上给诸位讲讲什么叫 RAG 吧,这个很有必要!博主我是一个 AI SAAS 的独立开发,在获客时,早早学会这个小妙招,会引导部分流量,到我的 RAG 专门搞的一个类似于 客服 的落地页里,而且很多是 AI 把客户送给我的,数量可能不多,但起码确实有,不能让 AI 把好处全占了。
这个 RAG 是我目前想到的唯一对抗 AI 这种只拿只白嫖,而啥也不赠与的坏坏的行为的一个解决方案,而且还能大大提高客户的留存时间。
为啥?ai 会抓博文、文章、评论区等一切内容,然后它 copy 走了,它赚钱了,赚流量了,把我饿死了。
现在我把我的内容,都装进我的私有 RAG 了,加上检索频率限制,哎,你猜怎么着?ai 啥也抓不走了,乖乖引导客户来我这里。然后客户在我的【个人客服】那边问东问西,一切文明和谐,诚信友善!
它的学名叫 Retrieval-Augmented Generation ,意思是 检索增强生成。
为什么有 RAG?
为什么要有它呢?因为过去的时候,大模型的知识局限于训练数据,如果数据比较混乱或空缺,则容易导致幻觉,而通过 RAG 就是缓解这个幻觉。反正,让模型不凭空大脑乱想了,而是去查资料,查到了,就说查到了,没查到就是没查到,老老实实说。
怎么理解?
有个大佬给其的一个比喻定义,很好。传统大语言模型,是闭卷考试,所有内容都在大脑里拼凑加想象。而 RAG 则是开卷考试,让事实能准确地知道源头,而且更有用的是,可以保护企业、组织的私有数据,这个检索过程是不公开的,你辛辛苦苦整理的文件,是不会一下子全暴露的。
闭卷考试,你想象,你定然是全靠记性去答题,那么你会不知不觉为了交卷而拼凑答案。
开卷考试,你因为允许去充分查找资料,那你则会稳重很多,答案质量更高。
这个应该没问题吧!
检索 R
在大语言模型内部,知识是有,但和人脑子里装的那种稀碎的碎片差不多,甚至更差。人脑还有空间时间观念去排序,在大语言模型脑子里,知识是高度压缩的,只是靠一个模模糊糊的概率在作为参考。
不是大语言模型给你胡说八道,而是它压根没那个概念,每个词就一个概率,它也不是活人,没有对错的非黑即白的概念。
而检索资料,则给了正确答案一个极大的概率权重,也就是【既定事实】!
模型的内部记忆,改动的代价很多,吃了成万亿计数,而训练成的内部参数,很难改的。但是外部的资料数据库,很容易改。
于是,一个良好的检索,这决定了 RAG 的结果质量,起码是上限。
这也就是为什么中国的 mirothinker ,套一个并不是国际顶尖的千问模型,就能实现不输国外几乎深度检索模型的效果,甚至更好。就是因为前者的检索做的好。
增强 A
当然,光把几十万字的原始资料片片断断给整理过来了,不能直接用。
还得处理。这个就是增强!精加工!
需要重排序(rerank)、清洗、长文本压缩成短文本....
然后将处理好的产物,再和用户问题匹配,构建一个好用的 提示词 。
之后基于这个提示词,推理,之后得到一个结果。
当然,这个只是简单说说,真正的运做,复杂太多了。
生成 G
这个时候,模型需要转换参数,让其变成一个严肃的甚至过分的老实人,让它基于增强的结果,组织语言,生成几乎不发散的答案。
然后答案就来了!
历史
对于外行人,了解这个 RAG 的大致原理,现在就够了。然后是历史。
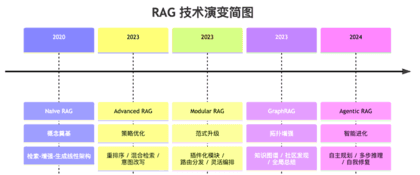
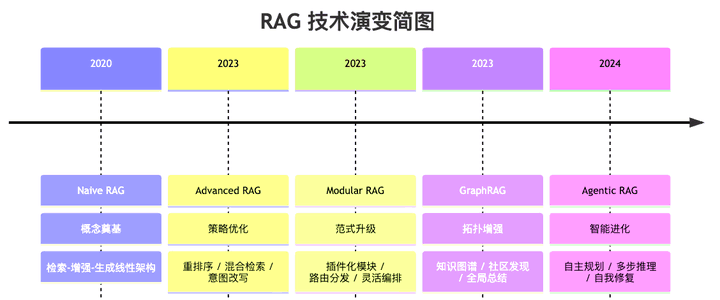
这个 RAG 的历史很久了,在 2022 年底 GPT 石破天惊之前,就有了。2020 年左右,Lewis 提出的。那时候的大语言模型很弱,这个 RAG 的过程更像是流水线,大语言模型没有什么逻辑,就是凭着微弱的语感,找到比较好的答案。那个时候是叫 Naive RAG 。
过程简单的很,原始文档分块儿,然后用 Embedding 模型转化为高维度向量,之后存入向量数据库。
然后用户的提问,也切块转化为向量,再进行一个余弦相似度计算,之后简单拼拼凑凑。不过那个时代,效果堪忧,上下文很短,精度极低,很直肠子,所以一直很小众。
(图来自 Vcats)
等 GPT 火起来,这个技术已经融入到了各大模型里面了,是一门很重要的技术了。
毕竟在线的 AI 对话,人们必然会问新闻。更新知识库代价大、精度差、口径矛盾多,所有会在线检索。
后来 Advanced RAG 解决了搜到且搜准,降低了干扰。就是优化了对用户提问的问题的理解,并且生成多个角度的提问,多线并行。
以及生成一个虚假的答案,让 ai 求正修正等。专有名词也做了特殊处理,上下文也切片等保持精度等等极速。
之后的 GraphRAG ,则优化算法,更加强了抗干扰能力。
最终形态是 Agentic RAG ,比较厉害是就是【反思】,不信任检索的内容,会不断进行对比,以及像人一样,评估现在够吗?还能再准吗?是否是幻觉?


{kind=link}